0day安全 | Chapter 25 漏洞分析方法概述
启程
Put your hand back in my shirt.
这是美版The Girl with The Dragon Tattoo中Lisbeth Salander的一句话。
已经到《0day安全》的第五篇章了。果毅力行,忠恕任事。
0 分析方法
作者认为一个人的漏洞利用技术是漏洞分析技术的基础,因为它将影响到你对漏洞严重程度的判断。这一点我很同意。
逆向是漏洞分析的主要组成部分,因此漏洞分析方法与其相似而有不同。具体如下:
- 静态分析:获得全局观
- 动态调试:回溯定位
- 补丁对比:简单有效,多被攻击者采用
1 动态调试
下断点是黑盒调试艺术的精髓。
源码调试与漏洞调试的不同在于:
源码调试:定位代码错误 -> 修改代码错误 -> 验证修改结果
漏洞调试:定位漏洞位置 -> 分析漏洞利用 -> 验证漏洞利用
1.0 断点技巧
畸形RetAddr断点
其思路是修改PoC中用于劫持控制流的返回地址为一个非法地址,如0xFFFFFFFF,从而引起非法内存访问错误,使得调试器中断。这时,我们可以从栈上找到最后一次函数调用,从而快速定位漏洞位置。第29章以“Yahoo!Messenger栈溢出漏洞”为实例演示这种技巧。
条件断点
它是一个带有条件表达式的普通INT3断点。当调试器遇到这类断点时,将计算表达式的值,若结果非零或表达式无效,则将暂停被调试程序。
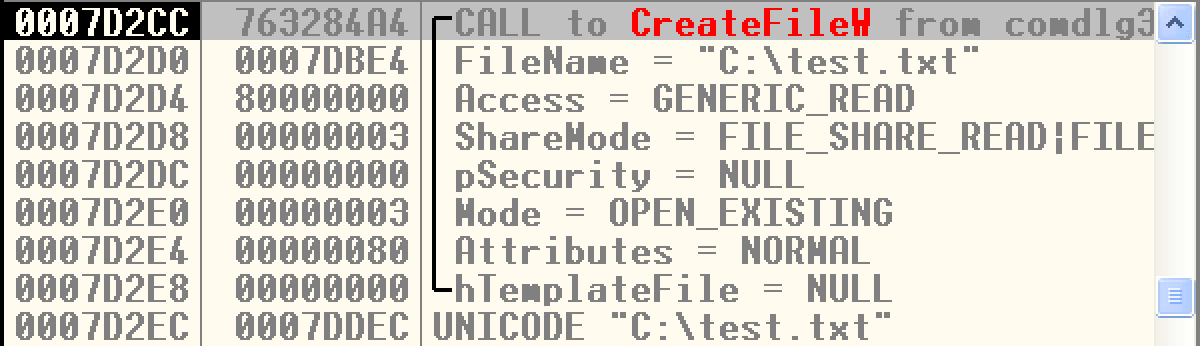
举例来说,我们用OD打开notepad.exe,希望只有当它打开或创建c:\\test.txt文件时才会在CreateFileW函数入口处中断,那么就可以在kernel32.dll中该函数入口处Shift + F2设置如下断点:

或者也可以使用OD的命令行插件下同样的断点:bp CreateFileW UNICODE[[ESP+4]]=="c:\\test.txt"。
接着,我们用记事本新建并保存c:\\test.txt,发现成功在此中断:

栈上信息清楚地展示了当前的函数调用:
下面我们深入了解一下OD的表达式。OD中表达式的语法格式如下(在大括号内的每个元素都只能出现一次,括号内元素顺序可以交换):
表达式 = 内存中间码 | 内存中间码<二元操作符>内存中间码
内存中间码 = 中间码 | {符号标志 大小标志 前缀} [表达式]
中间码 = (表达式)| 一元操作符 内存中间码 | 带符号寄存器 | 寄存器 | FPU寄存器 \
| 段寄存器 | 整型常量 | 浮点常量 | 串常量 | 参数 | 伪变量
一元操作符 = ! | ~ | + |
带符号寄存器 = 寄存器. // 注意最后有一个`.`
寄存器 = AL | BL | CL ... | AX | BX | CX ... | EAX | EBX | ECX ...
FPU寄存器 = ST | ST0 | ST1 ...
段寄存器 = CS | DS | ES | SS | FS | GS
整型常量 = <十进制常量>. | <十六进制常量> | <字符常量> | <API符号常量>
浮点常量 = <符点常量>
串常量 = "<串常量>"
符号标志 = SIGNED | UNSIGNED
大小标志 = BYTE | CHAR | WORD | SHORT | DWORD | LONG | QWORD | FLOAT \
| DOUBLE | FLOAT10 | STRING | UNICODE
前缀 = 中间码:
参数 = %A | %B // 仅允许在监察器[inspector] 中使用
伪变量 = MSG // 窗口消息中的代码
可以发现,上面这种描述方式和编译原理课程中对词法规则语法规则的描述是一样的。
注意,OD会将修饰符尽可能地放在地址最外面,所以[WORD [eax]]就是WORD [[EAX]]。
OD支持的运算符如下:
优先级 类型 运算符
0 一元运算符 ! ~ + -
1 乘除运算 * / %
2 加减运算 + -
3 位移动 << >>
4 比较 < <= > >=
5 比较 == !=
6 按位与 &
7 按位异或 ^
8 按位或 |
9 逻辑与 &&
10 逻辑或 ||
在计算时,中间结果以 DWORD 或 FLOAT10 形式保存。某些类型组合和操作是不允许的。例如:QWODRD 类型只能显示;STRING 和 UNICODE 只能进行加减操作(像C语言里的指针)以及与 STRING、UNICODE 类型或串常量进行比较操作;您不能按位移动 浮点[FLOAT] 类型,等等。
可以参考OllyDbg帮助手册获取更多信息。
条件记录断点
它是一种条件断点,可以额外记录已知函数表达式或参数的值。还是用上面的那个例子,我们先删除前面的条件断点,然后Shift + F4设置断点,记录每次记事本打开文件时的文件路径:
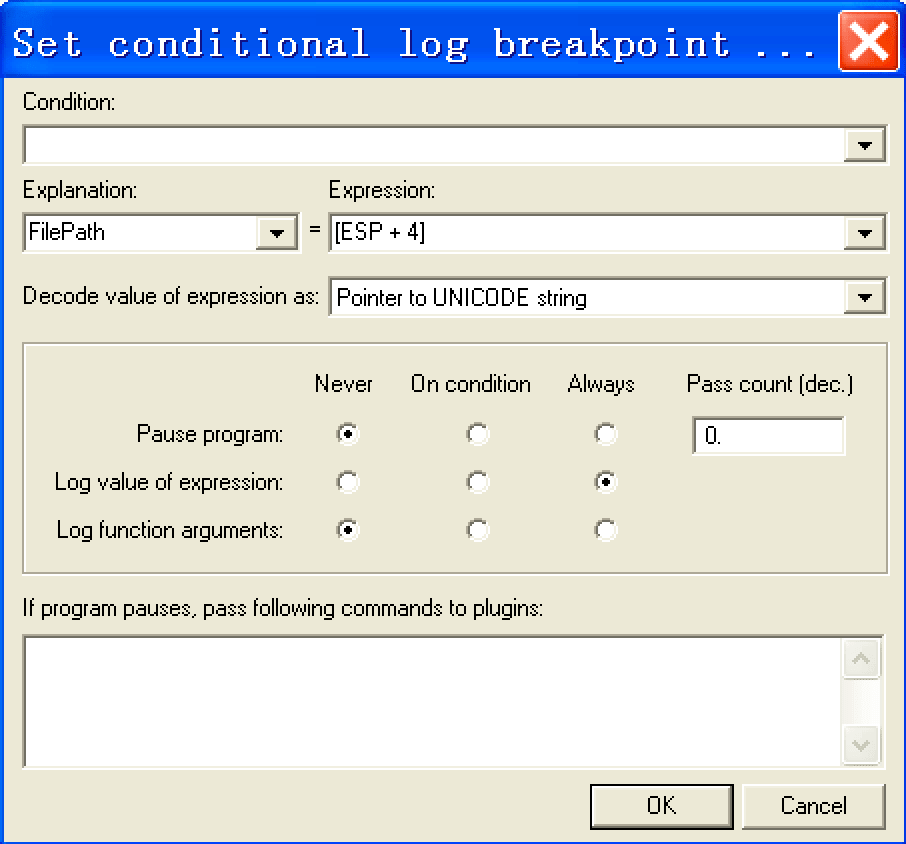
注意,我们设置不中断程序,也就是该断点仅仅起到记录的功能。测试一下,打开一个文件:

内存断点
内存断点如下:

可以对代码设置,也可以对数据设置。另外,OD还支持在内存段上设置“一次性断点”。比如在一个程序的代码段上设置(F2):

这样,一旦其中任何部分被访问,程序都会被中断。当我们希望控制流在进入其他模块后回到主模块立即停下来时,这非常有用。
硬件断点
该断点使用CPU提供的4个调试寄存器DR0~3来设置地址,DR7来设定状态。可以在代码上设置执行断点:

在数据上设置访问、写入和执行(这对于我们调试shellcode很有帮助)断点:

参考内存断点和硬件断点,内存断点与硬件断点的区别如下:
- 内存断点的原理是对目标内存页设置
PAGE_NOACCESS或PAGE_EXECUTE_READ属性,特点是效率低,但能够同时设置非常多的内存断点 - 硬件断点即借助CPU提供的调试寄存器下断点,由于只有4个硬件断点寄存器,所以同时最多只能设置4个硬件断点,但是它效率高
可以通过硬件断点的原理 —- OD各种断点的原理去了解OD各种快捷键背后的断点原理。
消息断点
在调试UI程序时常用消息断点。它属于条件断点,只不过用消息做表达式。我们做一个小实验来体会这种断点:用OD打开calc.exe,设置单击数字1时的消息断点,从而通过这个消息断点找到计算器程序中对点击数字1的响应代码。
首先,我们简单了解一下程序创建一个窗口的流程。通过VS 2008创建一个新的Win32工程,然后看一下它的示例代码:
LRESULT CALLBACK WndProc(HWND hWnd, UINT message, WPARAM wParam, LPARAM lParam){
// ...
switch (message){
case WM_COMMAND:
// ...
case WM_DESTROY:
PostQuitMessage(0);
break;
default:
return DefWindowProc(hWnd, message, wParam, lParam);
}
return 0;
}
ATOM MyRegisterClass(HINSTANCE hInstance){
WNDCLASSEX wcex;
wcex.lpfnWndProc = WndProc;
// ...
return RegisterClassEx(&wcex);
}
BOOL InitInstance(HINSTANCE hInstance, int nCmdShow){
HWND hWnd;
hInst = hInstance;
hWnd = CreateWindow(szWindowClass, szTitle, WS_OVERLAPPEDWINDOW,
CW_USEDEFAULT, 0, CW_USEDEFAULT, 0, NULL, NULL, hInstance, NULL);
// ...
ShowWindow(hWnd, nCmdShow);
UpdateWindow(hWnd);
return TRUE;
}
int APIENTRY _tWinMain(HINSTANCE hInstance,
HINSTANCE hPrevInstance,
LPTSTR lpCmdLine,
int nCmdShow){
// ...
MyRegisterClass(hInstance);
// 执行应用程序初始化:
if (!InitInstance (hInstance, nCmdShow))
return FALSE;
hAccelTable = LoadAccelerators(hInstance, MAKEINTRESOURCE(IDC_W));
// 主消息循环:
while (GetMessage(&msg, NULL, 0, 0)){
if (!TranslateAccelerator(msg.hwnd, hAccelTable, &msg)){
TranslateMessage(&msg);
DispatchMessage(&msg);
}
}
return (int) msg.wParam;
}
总结一下,就是:
- RegisterClass
- CreateWindow
- ShowWindow
- UpdateWindow
- 消息获取和处理循环。首先GetMessage,如果有消息到达,则将消息分派到回调函数(DispatchMessage),如果消息是
WM_QUIT,则推出循环
当有键按下、放开时,Windows产生WM_KEYDOWN和WM_KEYUP或WM_SYSKEYDOWN和WM_SYSKEYUP消息,它们包含的是键盘扫描码。TranslateMessage将扫描码转换为ASCII并在消息队列中插入WM_CHAR或WM_SYSCHAR消息。
综上,只要我们在GetMessage/TranslateMessage/DispatchMessage中任何一个下断点,都可以拦截数字1的单击消息。我们选择TranslateMessage。下面来动手实验:
OD加载calc.exe,F9使其运行,然后命令行下断点:
bp TranslateMessage MSG==WM_LBUTTONUP
成功:
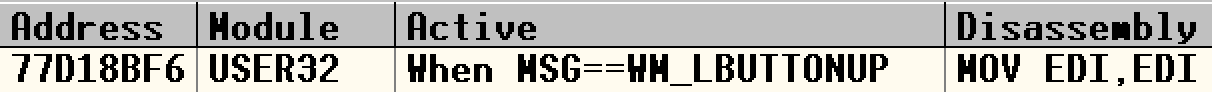
我们在计算器上按1,成功中断:

然后通过Alt + F9回到calc.exe模块,可以看到紧接着就要调用DispatchMessage:

DispatchMessage将调用calc.exe的窗口过程函数。我们先单步进入DispatchMessage,控制流注定要回到calc.exe模块中的窗口过程函数,所以我们使用一次性内存访问断点来在此中断:
F9,成功中断:

这里就是窗口过程函数。我们用IDA看一下这个函数:
int __stdcall sub_1006118(HWND hWnd, UINT Msg, int mode, LPCWSTR lpchText)
{
// ...
if ( Msg == 0x111 ) // 0x111 is WM_COMMAND
{
lpchTextb = (LPCWSTR)mode;
if ( (_WORD)mode == 0x5E && dword_1014D48 == 1 ) // 0x5E is 'Mod' button
lpchTextb = (LPCWSTR)109;
if ( HIWORD(mode) == 1 )
{
modeb = GetDlgItem(hDlg, (unsigned __int16)lpchTextb);
SendMessageW(modeb, 0xF3u, 1u, 0);
Sleep(0x14u);
SendMessageW(modeb, 0xF3u, 0, 0);
}
if ( (_WORD)lpchTextb != 403 && (_WORD)lpchTextb != 401 && (_WORD)lpchTextb != 0x192 )
sub_10042FC(v4, (unsigned __int16)lpchTextb);
return 0;
}
// ...
}
其中sub_10042FC函数将调用sub_100264B,它包含了大段的处理逻辑。至此,我们逐步逼近到对数字1的处理部分。
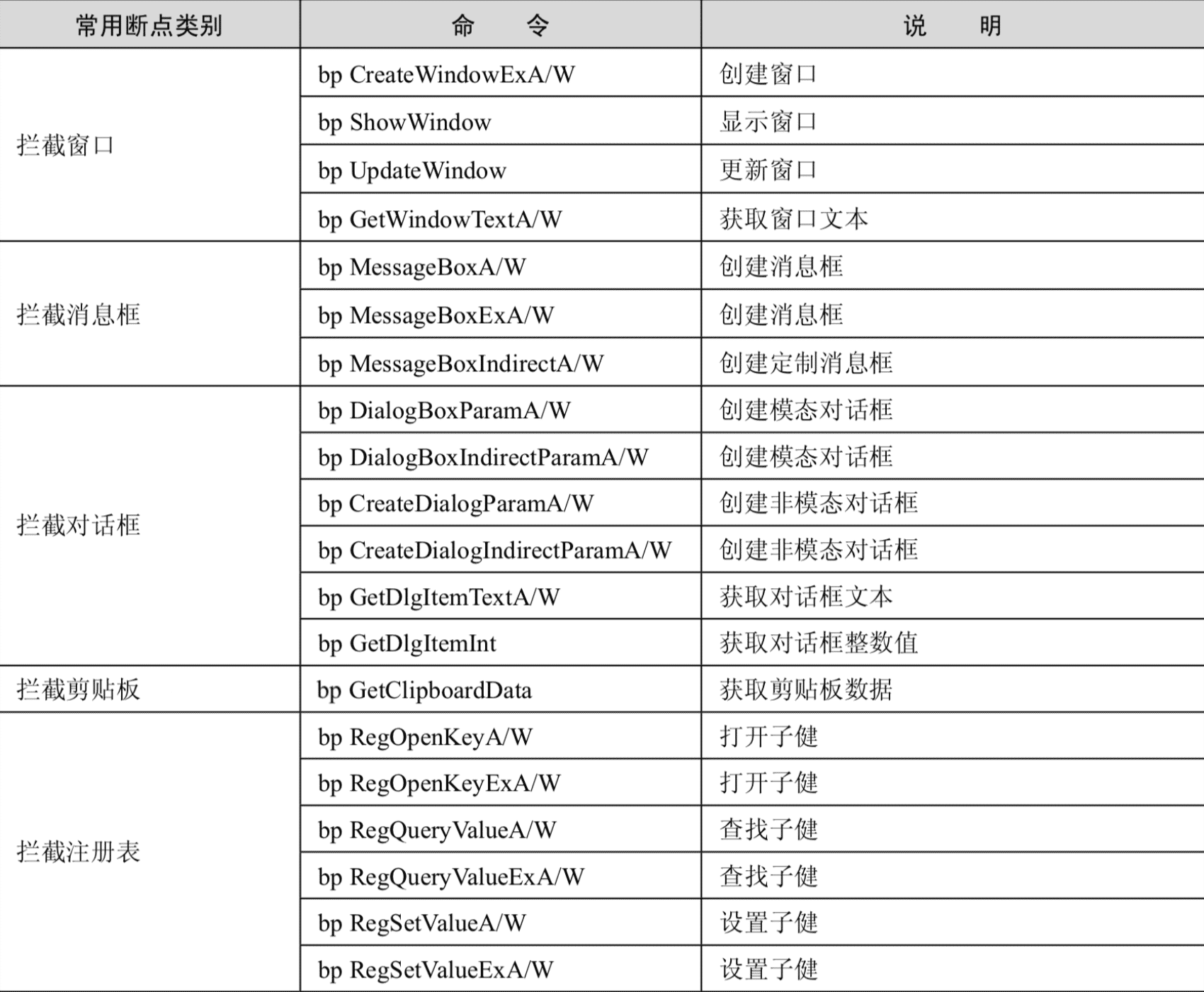
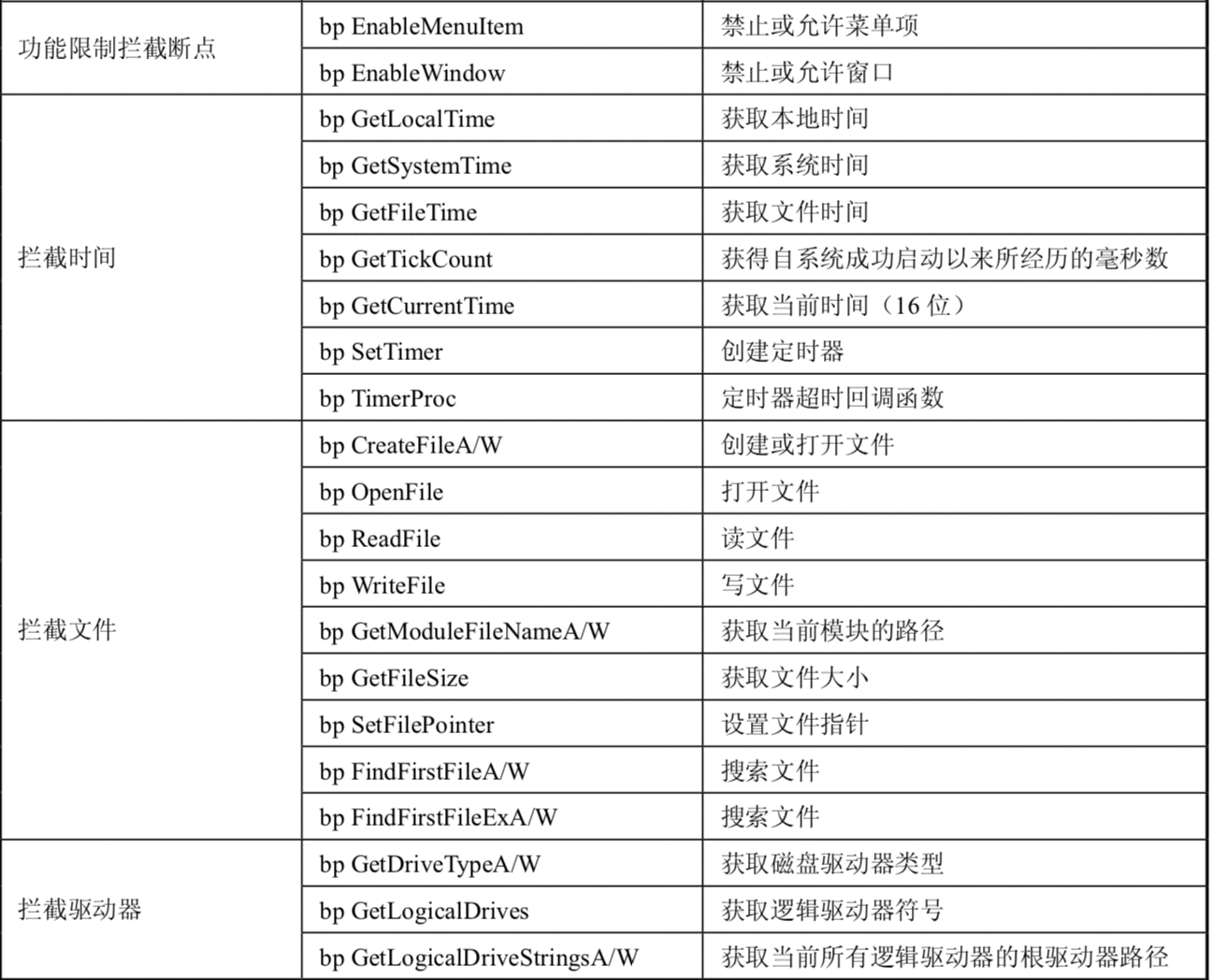
常用断点命令列表
1.1 回溯
回溯指的是,我们在借助断点定位到漏洞触发场景后,分析栈帧,获得更详细的函数调用情况。
以上一节的calc实验为例,追踪到1006118后,Alt + k打开栈调用窗口:
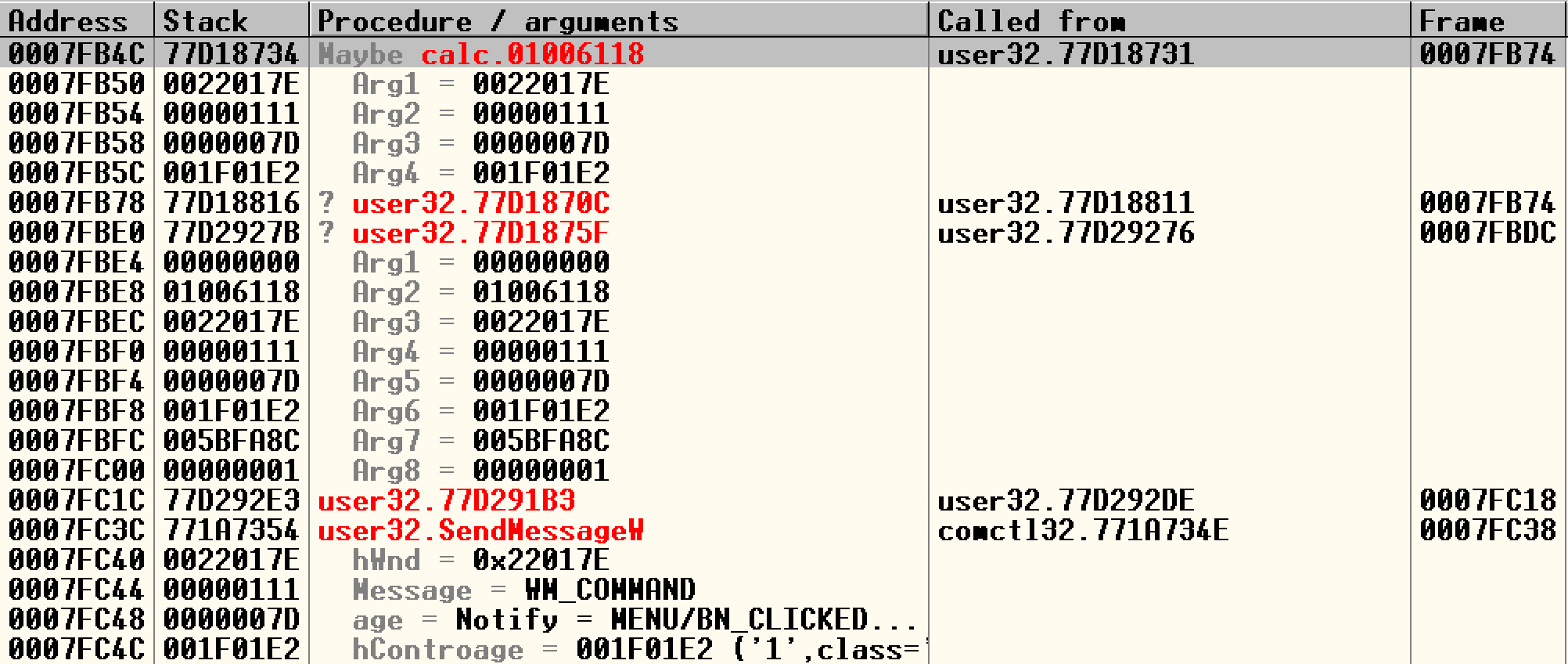
可以看到整个函数调用链。配合pdb符号文件使用效果更佳。
2 补丁比较
本节我们以MS06-040漏洞为例介绍BinDiff的使用。其中参考了缓冲区溢出分析第07课:MS06-040漏洞研究——静态分析去了解漏洞原理;参考了Re: Problems to solve去了解BinDiff的不足之处。
BinDiff的安装过程不再赘述。
首先分别用IDA打开修复前后的netapi32.dll文件,生成两个idb文件。接着可以使用IDA Pro的BinDiff插件分析,也可以直接打开BinDiff加载这两个idb文件分析。这里我选择后者,因为其更为强大、直观。
首先要说明的是,在MS06-040的场景中,BinDiff并不能很好地发挥作用。这是由于带有漏洞的早期netapi32.dll不包含debug信息,从而导致我们无法借助symchk下载对应的netapi32.pdb符号文件(或许可以下载,只是我的方法有问题?如果是这样,还请指教)。这是因为漏洞在于NetpwPathCanonicalize函数中被调用的一个函数上。我们可以为经过修补的netapi32.dll下载其对应pdb文件,然后用IDA加载,才知道这个函数叫做CanonicalizePathName。然而由于没有对应pdb文件,在早期的netapi32.dll的反汇编数据库中这个函数被命名为sub_xxx,所以在BinDiff中同一个函数在不同的idb中名称不一样,无法进行匹配,也就无法对比它们的流程异同了。
明确了这一点,我们在对早期netapi32.dll的反汇编窗口中把sub_xxx改名为CanonicalizePathName,然后保存这个idb文件。这样做是为了更直观地进行对比,毕竟我们现在是对一个老洞进行分析。如果是希冀分析新补丁去发现新漏洞,可能就没有这个上帝视角了。
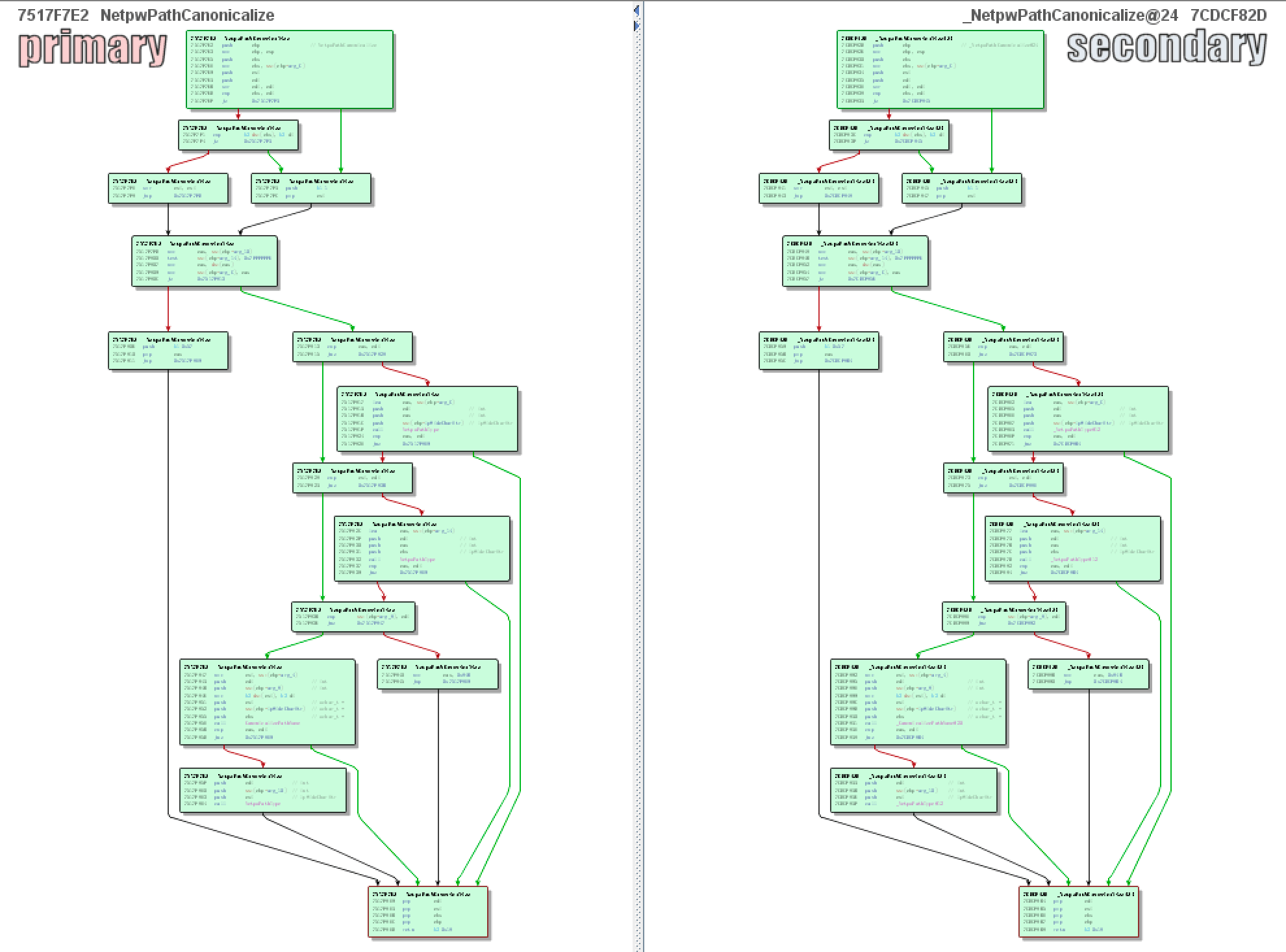
OK,我们先定位到NetpwPathCanonicalize:

可以发现它的流程没有变化:
我们进一步定位到CanonicalizePathName:

可以发现流程有了细微变化:
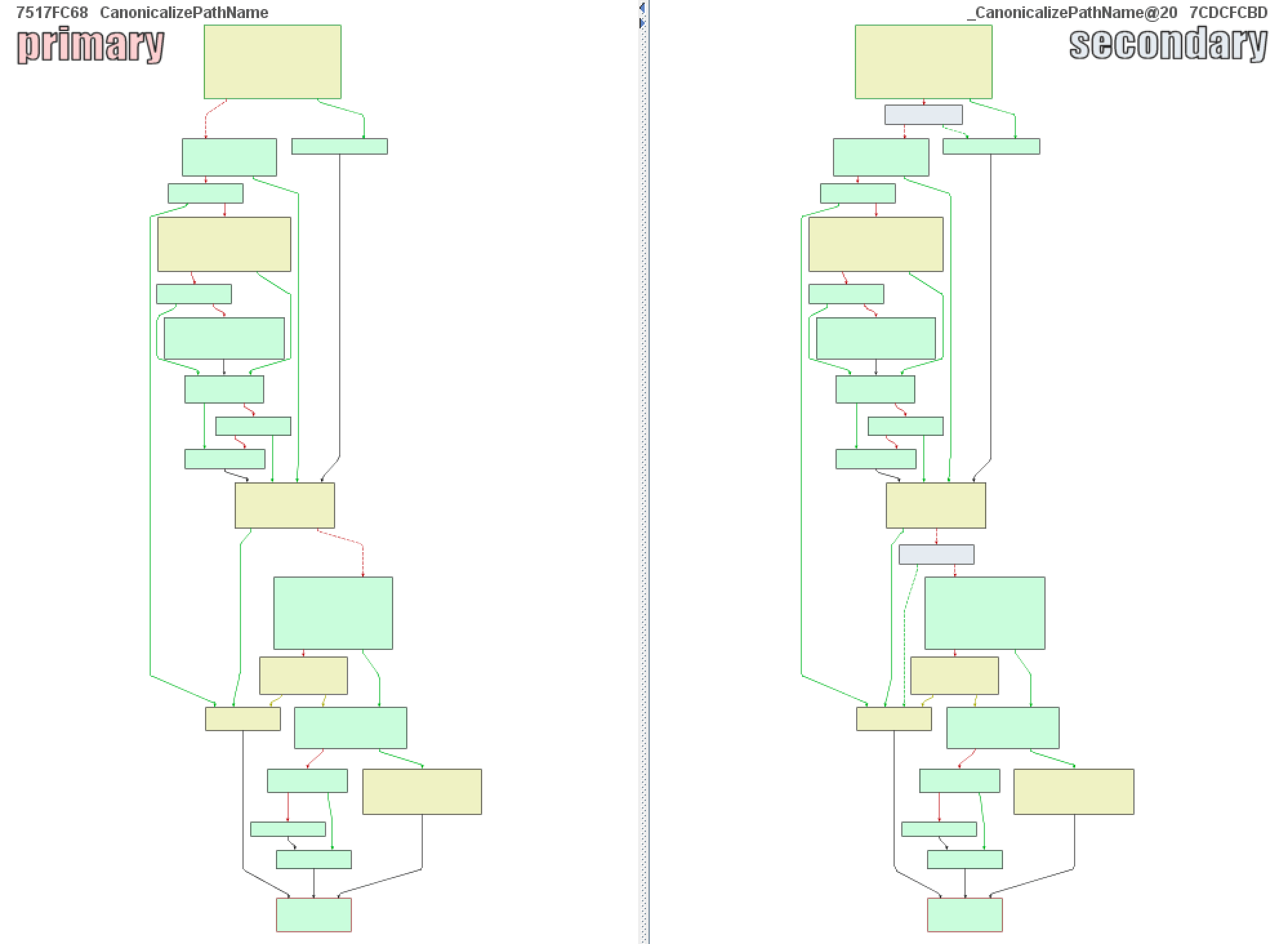
深入分析这些变化的地方,就可以发现漏洞所在。
补丁对比到此为止。下面我们进入IDA Pro去分析:
int __stdcall CanonicalizePathName(wchar_t *Source, wchar_t *Str, wchar_t *a3, int a4, int a5)
{
size_t sourceLen2; // esi@1
size_t sourceLen; // eax@2
__int16 v7; // ax@4
int result; // eax@14
size_t v9; // eax@15
__int16 v10; // [sp+Ah] [bp-416h]@4
wchar_t DeviceName; // [sp+Ch] [bp-414h]@4
sourceLen2 = 0;
if ( Source )
{
sourceLen = _wcslen(Source);
sourceLen2 = sourceLen;
if ( sourceLen )
{
if ( sourceLen > 0x411 )
return 123;
_wcscpy(&DeviceName, Source);
v7 = *(&v10 + sourceLen2);
if ( v7 != 92 && v7 != 47 )
{
_wcscat(&DeviceName, L"\\");
++sourceLen2;
}
if ( *Str == '\\' || *Str == '/' )
++Str;
}
}
else
{
DeviceName = 0;
}
if ( sourceLen2 + _wcslen(Str) > 0x411 )
return 123;
_wcscat(&DeviceName, Str);
// ...
return result;
}
DeviceName是栈上开辟的0x414h的空间,需要注意,这个空间的单位是字节,而后面_wcslen得到的sourceLen却是Unicode字符数,也就是说Source占用的字节数其实是2 * sourceLen。所以if ( sourceLen > 0x411 )实际上是一条没什么用的马奇诺防线,它后面的_wcscpy(&DeviceName, Source)可能导致溢出。但是溢出点并不在这里,因为上一层函数NetpwPathCanonicalize已经通过NetpwPathType限制了Source不能超过0x206字节。
问题在于后面的if ( sourceLen2 + _wcslen(Str) > 0x411 ),它同样没用,所以后面的_wcscat(&DeviceName, Str)也可能导致溢出,但由于并没有其他任何条件限制Str的长度,所以Str可以很长。极端情况下,sourceLen2 + _wcslen(Str) = 0x411,此时它们的总长度已经达到了0x822,很明显将溢出DeviceName。
这实质上是开发人员的疏忽,他们出于某种原因在当时没有考虑到Unicode字符串和普通字符串的区别,导致了漏洞。
这里仅仅做漏洞点分析,具体的漏洞利用放在下一章节进行。
总结
这一章非常很有价值。尤其是断点技术,它解答了我过去的一些困惑,并让我产生一种感觉:如果在过去的某些调试场景中我已经掌握这些不同的断点技术,那么未成功的调试可能就会成功,花了很多力气才做到的调试可能很轻松就完成。所谓工欲善其事,必先利其器。大抵如此。
原书中还讲解了以Paimei为代表的指令追踪技术。年代久远,这里不再尝试,需要时再使用。
另外,补丁对比界面很炫酷!
有时会很浮躁,要静下心来。