Linux IPC Notes
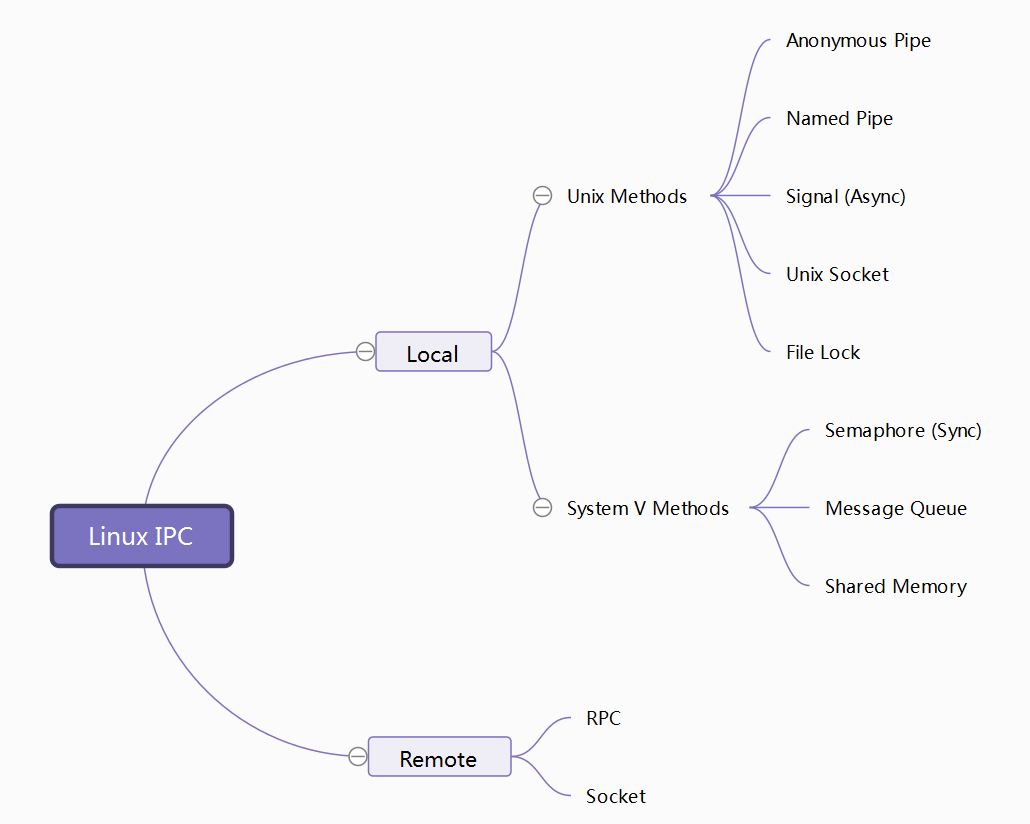
注:
- 上图中的RPC和socket本文不涉及
- 以下内容基于 Redhat 7,内核版本:3.10
- 感悟。strace简直是神器!
Anonymous Pipe
man 7 pipe # overview of pipes and FIFOS
man 2 pipe # see relative functions
具体操作比较简单,不再赘述。
容量限制
ulimit -p # to see the PIPE_BUF in system (4096 by default)
如上。一般系统的pipe缓冲区是4096,所以发送是有长度限制的。这一点参考socket编程,可以使用select函数或者poll以及epoll等方式做非阻塞轮询。
上面是2016-11-09写的记录,10号我来测试了一下,不太对。不唯书,不唯上,只唯实,这话不错。
实际情况是这样的,我写了一个test1-4,逻辑完全同test1-1,父进程给子进程发消息,修改的地方仅仅是:
#define RECV_BUF ?
有两个字符型数组分别存储父进程将要发送的内容和子进程收到的内容,定义如下:
char sendmsg[RECV_BUF];
char recvmsg[RECV_BUF];
// 初始化sendmsg
for(i = 0; i < RECV_BUF; i++)
sendmsg[i] = i % 26 + 'a';
父进程相关发送及打印语句为:
len = write(pipedes[1], sendmsg, RECV_BUF);
printf("send len: %d\n", len);
在子进程接收(read)的情况下,我将RECV_BUF增大至1,000,000,一直都是要求多少就能够发多少(后来改成10,000,000就段错误了,这可能与内存占用有关,不是这次研究的重点,可以先留个坑)。这跟生产者/消费者模型很像,消费者及时取走产品,生产者就能够再生产。
现在,我把子进程的接收语句注释掉——子进程不取走消息,只让父进程发。有意思了,RECV_BUF不大于65536时,打印语句正常输出,且数值为RECV_BUF的数值,一旦大于,则无输出语句,进程终止,连错误提示都没有。65536正好是unsigned short类型能够表示的最大长度(0 - 65535)。
从man 7 pipe获得了一些信息,大意是下面这样:
POSIX.1-2001规定,write向pipe写入长度小于PIPE_BUF的内容,这个操作一定是原子性的(标准保证),即写入操作是不受其他写入影响到的,不可分割的。写入多于PIPE_BUF的内容的操作可能是非原子性的,即,内核可能把当前进程写入的数据和其他进程写入的数据交错在一起。Linux上PIPE_BUF是4096字节(刚好是一个页的大小,通过getpagesize()函数查看)。进一步来说,还要看文件描述符是不是O_NONBLOCK,对于一个pipe是否有多个写入者,以及具体要写入的数据长度n。
......
更详细的可以参考man 7 pipe
上面的信息解释了一点——PIPE_BUF不是我以为的那种缓冲区长度限制,它仅仅保证原子性。然而还有两个地方无法解释:
- 为什么超过65536后进程终止,后续打印语句无法输出且无错误提示?发生了什么?
- 真正的限制为什么是65536(至少我当前环境是这个值)?是谁决定的?
第一个问题通过使用strace得到解答:
strace ./test
经筛选,有用的输出结果如下:
pipe([3, 4]) = 0
write(4, "abcdefghijklmnopqrstuvwxyzabcdef"..., 65537) = 65536
SIGPIPE {si_signo=SIGPIPE, si_code=SI_USER, si_pid=3485,si_uid=0}
+++ killed by SIGPIPE +++
如上。内核给进程发送了SIGPIPE信号。再man 7 signal查看信号:
SIGPIPE 13 Term Broken pipe: write to pipe with no readers
2016-11-10 20:00更新
++在FIFO部分做容量限制测试时我忽然发现PIPE部分这里是有问题的,FIFO部分中FIFO的限制也是65536,但是write阻塞在那里,进程并未收到SIGPIPE信号退出。我明白了,在PIPE部分,为了测试一次write写入的限制,我把接收一方的read函数注释掉了,这时候应该在close(pipedes[0])之前加一个sleep(10000)之类的语句,否则那个进程会不加停顿地直接关闭管道描述符并退出,向一个一端已经关闭的管道写入数据会收到SIGPIPE;而FIFO中我特意加入了这样的sleep语句。回过头来,在PIPE中让接收方sleep后,发送方并未收到SIGPIPE信号,而是同FIFO部分一样,阻塞在write那里。特此更正。++
第二个问题则更有意思:
man proc:
/proc/sys/fs/pipe-max-size (since Linux 2.6.35)
The value in this file defines an upper limit for raising the capacity of a pipe using the fcntl(2) F_SETPIPE_SZ operation. This limit applies only to unprivileged processes. The default value for this file is 1,048,576. The value assigned to this file may be rounded upward, to reflect the value actually employed for a convenient implementation. To determine the rounded-up value, display the contents of this file after assigning a value to it. The minimum value that can be assigned to this file is the system page size.
Linux 4.7内核fs/pipe.c部分源码(开头注释显示这还是1999年Linus Torvalds写的):
/*
* The max size that a non-root user is allowed to grow the pipe
* Can be set by root in /proc/sys/fs/pipe-max-size
*/
unsigned int pipe_max_size = 1048576; // 1MB
/*
* Minimum pipe size, as required by POSIX
*/
unsigned int pipe_min_size = PAGE_SIZE;
include/linux/pipe_fs_i.h:
/* Differs from PIPE_BUF in that PIPE_SIZE is the length of the actual memory allocation, whereas PIPE_BUF makes atomicity guarantees */
#define PIPE_SIZE PAGE_SIZE
我们试一下:
cat /proc/sys/fs/pipe-max-size
果然是1MB。
现在所有问题都归结到PAGE_SIZE上来,这个宏定义是否就是页大小?如果是,那么就应该是4KB,65536又从哪里来?
参考网上资料后,我发现include/linux/pipe_fs_i.h中还有一句:
#define PIPE_DEF_BUFFERS 16
原来自2.6内核后,尽管ulimit -p返回的是4KB,但是内核动态地分配了16个页给pipe,所以pipe缓冲区的总长度应该是64KB。版本2.6之前的内核,其pipe缓冲区长度应该是4KB(仅从别处得知以及个人推测,未验证)。
验证65536(64KB)
验证方法就是使用man proc中提到的fcntl函数,不具体介绍它了,代码如下:
#define _GNU_SOURCE // should be before all #include ...
#include <unistd.h>
#include <fcntl.h>
...
printf("%d\n", fcntl(pipedes[1], F_GETPIPE_SZ));
真棒,打印的就是65536 : )
拓展一下,我们可以给fcntl传递F_SETPIPE_SZ参数去修改这个值。
第二个问题总结
对于2.6以后的内核,建立一个pipe,系统就给分配64KB;还有一个1MB,这个值是非特权用户使用fcntl函数修改pipe长度能够到达的上限。root用户的程序则不受限制,且root可以通过修改/proc/sys/fs/pipe-max-size来更改这个上限。但是要注意,在不使用fcntl的情况下,进程一次write写入pipe的最大值就是64KB,这一点对于所有用户都是一样的。
方向
无名管道属于单向通信,一个管道只允许一端写一端读,而且两个进程分别只能拥有一端。测试发现如果尝试父进程先写子进程先读,子进程再写父进程再读,两个进程都会阻塞在那里。如果想要双向通信,则要建立两个pipe。
2016-11-13 22:34 注:
跟任丘与讨论并实践后发现,管道本身是单向的,这个单向指的是从一个描述符到另一个描述符。但是由于父子进程共享了pipedes[0]和pipedes[1],所以它俩都可以使用这两个描述符,故对于父子进程来说,是可以双向通信的。
数据类型
任意数据类型(和socket传输类似,不同之处在于pipe是本地传输,对于多字节数据类型不必转换网络/主机序)。
独立进程能否使用?
参考man,pipe用于related processes之间。
我本来想在一个进程中创建一套pipe,然后打印出fd,并向pipedes[1]中写入,在另一个独立进程中从pipedes[0]中读。然而另一个进程无法打开这个pipe,因为已经有fd了,且pipe是匿名的,所以不能用open函数去带一个文件名参数去打开,而pipefd本身又是进程私有的资源,所以独立进程之间是不能使用pipe传递数据的。
++读UNP volume2第四章时发现小字部分Stevens先生说从技术上来讲pipe是可以用于不相关进程之间的通信的,这里先标记一下,等IPC都过一遍了再回来填坑。++
注意细节
假设父进程写,子进程读:
- 父进程先关闭读描述符,子进程先关闭写描述符,不要浪费资源,也防止出错
- 在读写发生错误的时候退出前先关闭描述符,保证万无一失
- 采用while+total+len的循环读写方式
- 发送字符串不要带尾零(提高效率)
- 凡是涉及父子进程的程序都要处理或者显式忽略SIGCHLD信号
- 多个程序如果头文件相同可以统一写在一个.h文件中
Named Pipe (FIFO)
介绍
man fifo # something about fifo
上面的资料中有几个重点的地方:
- 进程通过fifo传递信息是经由内核而不写入filesystem的。fs仅仅提供一个指针帮助进程通过名字找到fifo
- fifo可以在非阻塞模式下打开
- 使用mkfifo创建fifo
- fifo存储的信息在两进程结束后自动丢失,这与普通文件不一样
- fifo必须同时打开读写两端才可以传递消息。fifo为阻塞型时(缺省),打开一端时
open函数会阻塞,直到另一端打开。fifo为非阻塞型时,读端可以成功打开,如果读端未打开,打开写端会失败。如果在读未打开情况下写入,会收到SIGPIPE信号 - Linux下一个进程可以同时打开读写端,但POSIX未对此定义。如果一个进程使用一个fifo和自己通信(既读又写),要注意可能出现死锁
shell测试
mkfifo fifotest # you can also use mknod fifotest p
cat ./makefile > fifotest &
cat < fifotest
C编程
man 3 mkfifo
容量限制
经测试,同PIPE,缺省情况下一次写入最多为65536字节。
方向
一个fifo只能是一个进程写一个进程读,或者一个进程自己写和读。
如果一个进程要既写又读,那么就需要以O_RDWR模式打开fd,我在父子进程中均以读写模式打开fifo,父进程给子进程发消息(后来在UNP v2第四章中看到,Stevens说FIFO不能以read-write方式打开,因为它是半双工的):
// parent
pid = getpid();
printf("parent pid: %d\n", pid);
if((fd = open(FIFO, O_RDWR)) < 0){
perror("open");
return ERROR;
}
printf("Send to child: %s\n", sendmsg);
len = write(fd, sendmsg, strlen(sendmsg));
// child
if((fd = open(FIFO, O_RDWR)) < 0){
perror("open");
return ERROR;
}
printf("Read from parent\n");
total = 0;
sleep(9);
while((len = read(fd, recvmsg+total, RECV_BUF)) > 0)
total += len;
printf("what?\n");
if(len == -1){
perror("read");
close(fd);
return ERROR;
}
recvmsg[total] = '\0';
close(fd);
printf("Read from parent: %s\n", recvmsg);
ps -ef显示父进程退出,子进程还在。使用strace -p ChildPID跟踪发现子进程阻塞在read函数,这说明子进程没有收到父进程发送的数据。
进一步测试,在父进程write函数后面紧跟read函数读,发现可以读到父进程刚刚写入的内容。这说明fifo是单向的。如果想要双向通信,需要建立两个FIFO。
数据类型
同PIPE。
独立进程能否使用?
有名字当然可以啦。直接open打开就好,关于open的细节之前已经讲了一些,这里要补充的是一个思考:如果是父子进程关系,那么在子进程fork出来前FIFO就已经建好了,所以打开时不会失败;但是独立进程之间并没有这样的联系,而mkfifo函数只在一个程序中执行,那么我们肯定要先运行这个程序。我的想法是,可以用signal来保证同步,如果我们先运行了没有mkfifo的程序,它会睡眠,等带有mkfifo的程序把FIFO创建好了再给它发信号唤醒(从后面的独立进程试验中可以看出确实存在这个问题)。
关于两进程使用两FIFO双向通信的注意点
死锁
// Process-A.c
readfd = open(FIFO1, O_RDONLY); // step1
writefd = open(FIFO2, O_WRONLY); // step2
// Process-B.c
readfd = open(FIFO2, O_RDONLY); // step1
writefd = open(FIFO1, O_WRONLY); // step2
由于FIFO一端打开时open函数会阻塞直到另一端也打开,所以上面两个进程都很巧妙(不幸)地阻塞在step1。正确应为:
// Process-A.c
writefd = open(FIFO1, O_WRONLY); // step1
readfd = open(FIFO2, O_RDONLY); // step2
// Process-B.c
readfd = open(FIFO1, O_RDONLY); // step1
writefd = open(FIFO2, O_WRONLY); // step2
启动时序
如上面的代码,FIFO1先被两个进程打开,所以带有mkfifo(FIFO1, FILE_MODE)的程序(假设为A)要先运行,否则会出现问题。我的程序中有下面的语句:
unlink(FIFO1);
如果B先启动,FIFO1在之前已经存在(上一次测试留下的),那么open成功,但是A启动时,会unlink掉旧的FIFO1,创建新的,导致它俩的FIFO1不同,最后都阻塞在那里。如果没有旧的FIFO1,那么B以读方式打开会直接失败,错误提示没有文件。如果B以写方式打开,则B会创建一个普通文件FIFO1,A启动后unlink这个文件并创建真正的FIFO1,同样无法通信。
close时序
最初伪代码如下:
// Process A
write();
...
read();
...
close(writefd);
close(readfd);
// Process B
read();
...
write();
...
close(readfd);
close(writefd);
A在write完后没有close,导致B的read一直阻塞在那里,它以为A还要发;之后A开始read,也会一直阻塞在那里,因为B还卡在read处。正确的顺序应为:
// Process A
write();
close(writefd);
...
read();
...
close(readfd);
// Process B
read();
close(readfd);
...
write();
...
close(writefd);
以上所有问题均使用strace调试。
注意细节
- 可以用宏定义的形式统一管道名:
#define FIFO "/tmp/fifotest"
- 在一切开始前先用
unlink(FIFO)进行“如果文件存在则删除” - 一般给
mkfifo传递的mode参数是0644好一些,使用宏定义:
#include <sys/stat.h>
#define FILE_MODE (S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH)
- 一个有意思的地方:./02/目录下有两个FIFO,当我在./03/下执行
cp ../02/* ./命令时会被阻塞,复制时只有不包含FIFO文件才能成功。留坑。
Signal
man 7 signal
man 2 sigaction
注意细节
- 信号来时,进程可以有几个行为:执行系统默认操作/捕捉/忽略/阻塞
- SIGKILL/SIGSTOP不能被捕捉,忽略,阻塞
- 多值信号的多值是针对不同体系结构而言的,如SIGUSR1在x86上是10,具体的可以使用
kill -l来查看 - 忽略与阻塞:
- 忽略指系统仍然传递该信号,但是相应进程对信号不做任何处理
- 阻塞指系统不传递该信号,显示该进程无法接收该信号,直到该进程信号集改变
- 常用的父进程忽略子进程退出信号其实是一个宏:
#define SIG_IGN ((_sighandler_t) 1) // this one
#define SIG_DEL ((_sighandler_t) 0)
#define SIG_ERR ((_sighandler_t) -1)
man 2 signal指出signal函数在不同版本的Unix和Linux系统中的行为是不一样的,所以不推荐使用这个函数设置自定义信号处理程序,推荐使用sigaction。signal函数唯一合适的用途是设置SIG_DEL或者SIG_IGN
测试
A每隔5秒依次循环向B发送下表中前3个信号。
/* Signals used in this test:
* signal B's behavior
0 SIGCONT printf("SIGCONT: continue\n");
1 SIGURG printf("SIGURG: continue\n");
2 SIGUSR1 printf("SIGUSR1: continue\n");
3 SIGUSR2 printf("SIGUSR2: exit\n");
4 SIGTERM printf("SIGTERM: exit\n");
5 SIGKILL printf("SIGKILL: continue\n");
*/
int Sig[SIG_NUM] = {
SIGCONT,
SIGURG,
SIGUSR1,
SIGUSR2,
SIGTERM,
SIGKILL
};
B中handler部分为:
void Handler0(int sig);
...
void Handler5(int sig);
struct sigaction act[SIG_NUM], oact[SIG_NUM];
void (*Handler[SIG_NUM])(int) = {
Handler0,
Handler1,
Handler2,
Handler3,
Handler4,
Handler5
};
for(i = 0; i < SIG_NUM; i++){
act[i].sa_handler = Handler[i];
sigemptyset(&(act[i].sa_mask));
act[i].sa_flags = 0;
sigaction(Sig[i], &act[i], &oact[i]);
}
列表中后3个终止信号通过控制台发送。可以发现,前5个信号均成功被B捕捉,SIGKILL信号则捕捉失败,B进程直接退出,控制台显示”已杀死”。
sigaction
有必要对sigaction函数研究一下。
int sigaction(int signum,
const struct sigaction *act,
struct sigaction *oldact);
第一个参数是信号,没什么说的。
第三个参数记录之前对此信号的处理信息。
第二个参数设置信号处理信息:
struct sigaction {
void (*sa_handler)(int); // 1
void (*sa_sigaction)(int, siginfo_t *, void *); // 2
sigset_t sa_mask;
int sa_flags;
void (*sa_restorer)(void);
};
上面注释标明1,2,这两部分只用其一,不要同时使用。如果sa_flags标志设置了SA_SIGINFO,则表示你要用2,否则是1。1和signal函数类似,直接填上你的信号处理例程就好;2的功能更强大,可以传递其他上下文信息。
探究
普通用户br运行A,root运行B
题外话,这里也有个有意思的地方:在
su - br后,ps -ef看到su - br进程仍在,属于root,下一个进程紧接着是br的bash,这解释了为什么在br的bash中exit后又可以退回到root的bash,应该是su - br进程收到子进程(br的bash)退出信号后退出了。
strace结果显示,A这边的kill会返回-1(EPERM (Operation not permitted))。
信号能否携带数据?
信号本身不可以携带数据。但是个人以为,信息本来就是编码传递的,两个进程可以约定使用信号进行编码,比如用SIGUSR1当做0,SIGUSR2当做1,每8个作为一组,这样就可以对应ASCII了(也许没有什么意义,也许有)。
Message Queue
POSIX标准和System V标准均包含消息队列,两者有所差异。下面先介绍System V版本的,再介绍POSIX的(Linux对于两种都支持)。
System V Message Queue
后面简称“消息队列”,不再加System V前缀
System V IPC简介
在后面介绍共享内存/信号量机制时将不再介绍
ipcs命令可以列出当前系统使用的IPC工具(消息队列/信号量/共享内存):
--------- 消息队列 -----------
键 msqid 拥有者 权限 已用字节数 消息
------------ 共享内存段 --------------
键 shmid 拥有者 权限 字节 nattch 状态
--------- 信号量数组 -----------
键 semid 拥有者 权限 nsems
Key/ID
拥有者/权限
IPC对象相关函数
| Message queues | Semaphores | Shared memory | |
|---|---|---|---|
| Header | sys/msg.h | sys/sem.h | sys/shm.h |
| create or open | msgget | semget | shmget |
| control | msgctl | semctl | shmctl |
| IPC operation | msgsnd/msgrcv | semop | shmat/shmdt |
消息队列模型
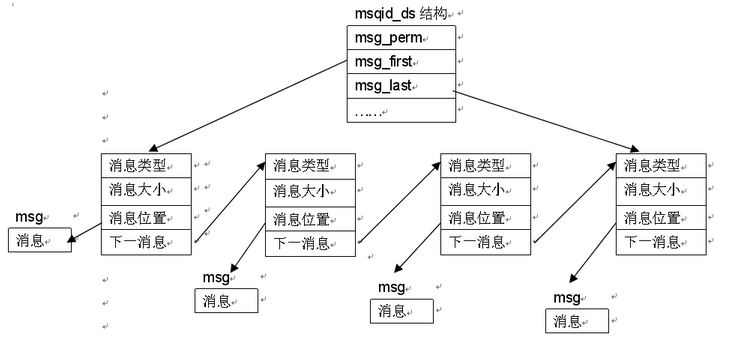
数据类型
char型数组。也可以把其他类型转换成char传递。
和管道的区别
最明显的地方,一个管道只允许单向通信,消息队列可以双向通信。
消息队列中消息是可以设定类型的,进程可以选择性接收,管道是一股脑接收。
容量限制
参考/usr/include/linux/msg.h:
双向通信
可以设置不同的消息类型,每一端仅仅接收某种消息类型,两端无交集,这样就实现了双向通信。当然,最好能够设置为IPC_NOWAIT,这样就不会阻塞了。
注意细节
注意用于接收消息的自定义结构体,其中的mtype的类型是long!不是int!在64位机器上,long占8字节,int占4字节,一般来说,小转大不会出错,但这里很巧,恰好是一个结构体:
struct msgbuf{
int mytype; // 'long' is right
char mtext[512];
}
现在的问题是,你发送端把一个int型数3当做类型发过去了,没关系;但是人家接收端在接收的时候是按照一个结构体进行判断的,也就是说你的结构体的前8个字节被人家当做了类型!这就导致错误了。
总结:一定要老老实实地使用数据类型。
POSIX Message Queue
【留坑】
What is the difference?
【留坑】
Shared Memory
特性
共享内存用于进程间大量数据传输。将文件从管道传输到另一个文件需要复制4次(file->server->pipe/fifo->client->file),通过共享内存只需两次(file->shared memory->file)。
互斥
一般共享内存配合信号量使用,为了防止多个进程同时对共享内存空间写操作。
独立进程能否使用?
Sure.
注意细节
在使用完毕共享内存后记得卸载,删除。
Unix Socket
man 7 unix
Unix Socket与TCP/UDP Socket的异同
基本相同。除了地址类型要选择为sockaddr_un,family为AF_UNIX外基本一样。
Unix Socket与其他IPC方式的异同
Unix Socket有没有阻塞/非阻塞之分?能否用select函数控制读写?
可以使用select函数控制读写。
首先,我使用fcntl函数将两端的socket均设置为NONBLOCK模式。
在我的程序组test6-3-1(A)和test6-3-2(B)测试中,A给B发送大量字符串,打印发送长度;B接收并打印发送长度。A只进行一次write,B多次读,直到读不出来。结果显示,即使A发送999999字节数据,依然可以发送成功,B可以接收到999999字节数据。
File Lock
Linux系统中常用两种锁:协同锁,强制锁。
协同锁
协同锁分为读锁和写锁。读锁要求在锁期间,其他进程不可写;写锁要求在锁期间,其他进程不可读写。
所谓协同锁,不是真的锁。比如A进程设置写锁,对文件执行写入操作;同时B进程是可以对同一文件执行读操作的。只有B进程在读操作之前请求一个读锁,这个读锁才会阻塞B进程,直到A把写锁取消。
void mylock(int fd, int op)
{
struct flock lock;
lock.l_whence = SEEK_SET;
lock.l_start = lock.l_len = 0;
lock.l_pid = getpid();
lock.l_type = op;
if(fcntl(fd, F_SETLKW, &lock) == -1){
close(fd);
oops("fcntl", ERROR);
}
}
如上,是常用的函数。我们可以传入的op为F_WRLCK,F_RDLCK,F_UNLCK,见名知义。
强制锁
man 2 fcntl
Mandatory locking
(Non-POSIX.) The above record locks may be either advisory or mandatory, and are advisory by default.
Advisory locks are not enforced and are useful only between cooperating processes.
Mandatory locks are enforced for all processes. If a process tries to perform an incompatible access
(e.g., read(2) or write(2)) on a file region that has an incompatible mandatory lock, then the result
depends upon whether the O_NONBLOCK flag is enabled for its open file description. If the O_NONBLOCK flag
is not enabled, then system call is blocked until the lock is removed or converted to a mode that is com‐
patible with the access. If the O_NONBLOCK flag is enabled, then the system call fails with the error
EAGAIN.
To make use of mandatory locks, mandatory locking must be enabled both on the file system that contains
the file to be locked, and on the file itself. Mandatory locking is enabled on a file system using the
"-o mand" option to mount(8), or the MS_MANDLOCK flag for mount(2). Mandatory locking is enabled on a
file by disabling group execute permission on the file and enabling the set-group-ID permission bit (see
chmod(1) and chmod(2)).
The Linux implementation of mandatory locking is unreliable. See BUGS below.
BUGS:
The implementation of mandatory locking in all known versions of Linux is subject to race conditions which
render it unreliable: a write(2) call that overlaps with a lock may modify data after the mandatory lock
is acquired; a read(2) call that overlaps with a lock may detect changes to data that were made only after
a write lock was acquired. Similar races exist between mandatory locks and mmap(2). It is therefore
inadvisable to rely on mandatory locking.
References
UNP volume 2
《Linux高级程序设计》 杨宗德 邓玉春
linux中的PIPE_SIZE与PIPE_BUF,管道最大写入值问题
Pipe buffer size is 4k or 64k?
Re: PIPE_SIZE aspects
Bypassing the 64K pipe buffer limit
UNIX Domain Socket IPC